How to start using Data Package
There are many alternatives when it comes to Data Package Standard implementations. We will cover a few the most popular options which will be a good starting point.
Open Data Editor
The simplest way to start using the Data Package Standard is by installing Open Data Editor (currently, in beta):
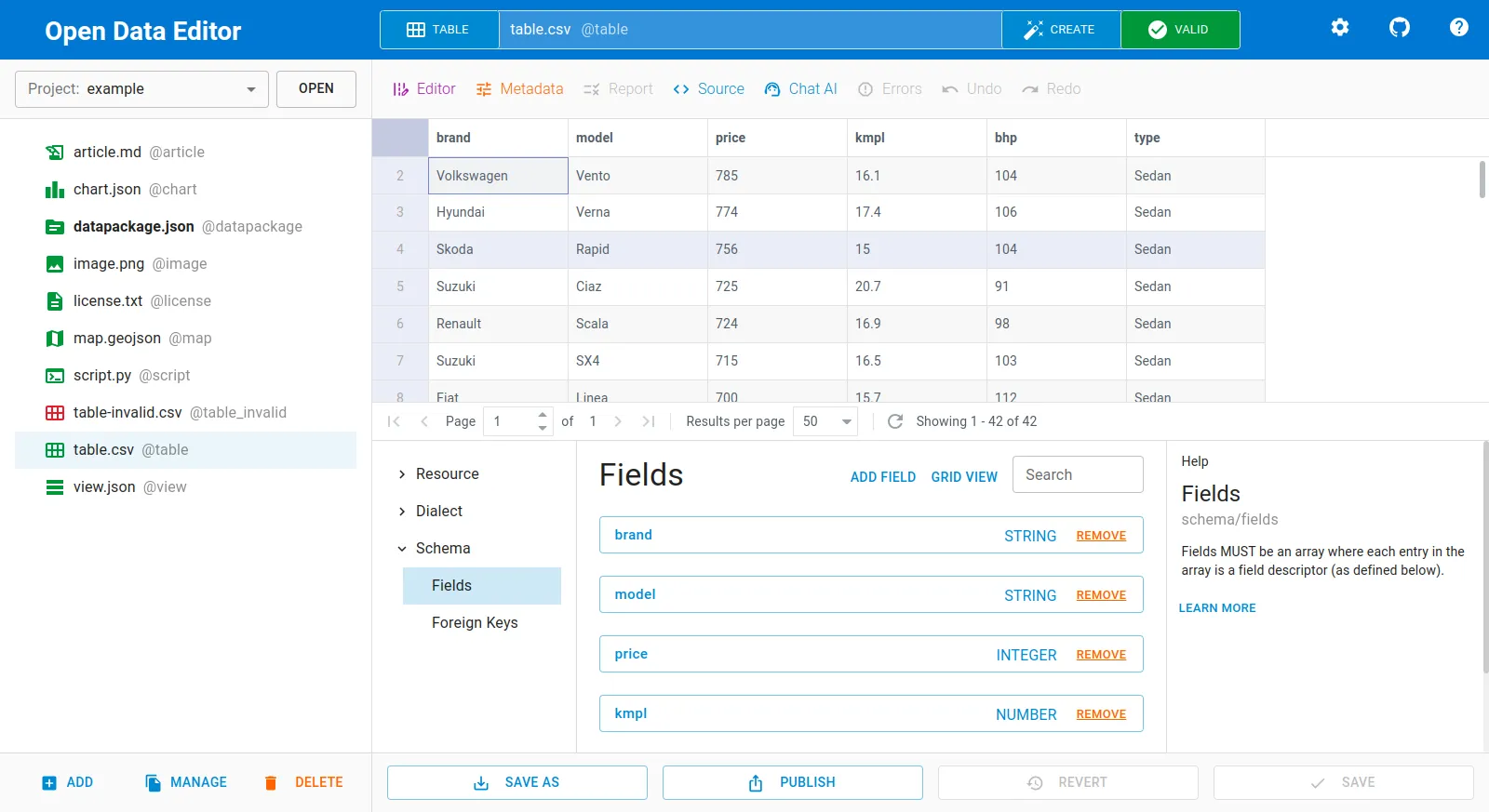
You can use the visual interface as you usually do in any modern IDE, adding and moving files, validating data, etc. Under the hood, Open Data Editor will be creating Data Package descriptors for your datasets (can be explicitly done by creating a dataset), inferring metadata, and data types. When the data curation work is done a data package can be validated and published, for example, to CKAN.
Please refer to the Open Data Editor’s documentation to read about all the features.
frictionless-py
If you prefer a command-line interface, or Python, there is frictionless-py, a complete framework for managing data packages. Here are main commands available in CLI:
frictionless describe # to describe your datafrictionless explore # to explore your datafrictionless extract # to extract your datafrictionless index # to index your datafrictionless list # to list your datafrictionless publish # to publish your datafrictionless query # to query your datafrictionless script # to script your datafrictionless validate # to validate your datafrictionless --help # to get list of the commandfrictionless --version # to get the versionPlease refer to the frictionless-py’s documentation to read about all the features.
frictionless-r
For the R community, there is frictionless-r package that allows managing data packages in R language. For example:
library(frictionless)
# Read the datapackage.json file# This gives you access to all Data Resources of the Data Package without# reading them, which is convenient and fast.package <- read_package("https://zenodo.org/records/10053702/files/datapackage.json")
package
# List resourcesresources(package)
# Read data from the resource "gps"# This will return a single data frame, even though the data are split over# multiple zipped CSV files.read_resource(package, "gps")Please refer to the frictionless-r’s documentation to read about all the features.